
AI代理上下文工程入门:从Manus构建经验学习
AI代理上下文工程入门:从Manus构建经验学习。早上看到 Manus的文章,发现很多内容属于“每个字都理解,但是需要大量的知识点来补充才能更好的消化和应用”,看到很多大佬的解读都是面向纯技术的,我打算在Gemini+Claude的帮助下写一个小白也能看到的解析。所有图片源于Manus的配图。

早上看到 Manus的文章,发现很多内容属于“每个字都理解,但是需要大量的知识点来补充才能更好的消化和应用”,看到很多大佬的解读都是面向纯技术的,我打算在Gemini+Claude的帮助下写一个小白也能看到的解析。所有图片源于Manus的配图。
原文见:https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-Manus
什么是上下文工程?为什么重要?
上下文工程(Context Engineering)是指设计和优化输入给AI模型的文本内容(即"上下文"),使模型能够更好地理解任务并产生期望的输出。对于AI代理(能够自主执行任务的AI系统)来说,这一点尤为重要。
想象一下:上下文就像是AI的"工作记忆",包含了它需要了解的所有信息。如何组织这些信息,决定了AI的表现好坏。
选择方案:训练新模型 vs 利用现有模型的上下文学习能力
文章开头讨论了两种构建AI代理的方法:
- 训练专门的模型:从开源基础模型开始,针对特定任务进行训练和微调
- 上下文学习:利用现有大型语言模型(如GPT、Claude)通过上下文提示来完成任务
为什么Manus选择了上下文学习?
- 历史教训:作者分享了他在NLP领域十年的经验。以前(BERT时代,约7年前),每次想让AI做新任务,都需要重新训练模型,这个过程可能需要数周时间。
- 快速迭代:使用上下文学习,可以在几小时内而非几周内发布改进,这对于快速发展的产品至关重要。
- 适应模型进步:如果模型发展是"涨潮",那么使用上下文学习的产品就像"船"一样能随之升高,而不是固定在海底的"柱子"。
作者幽默地将他们的开发过程称为"随机研究生下降"(Stochastic Graduate Descent),指的是通过不断尝试不同方案、调整提示词和进行实验来找到最佳解决方案的过程。
KV缓存:理解AI代理的性能关键
什么是KV缓存?
KV缓存(Key-Value Cache)是一种技术,用于存储模型已经处理过的文本对应的内部表示,避免重复计算。简单来说:
- 当AI模型读取文本时,它会将文本转换为内部表示(键值对)
- 如果下次遇到相同的文本,可以直接使用缓存的表示,而不用重新计算
- 这大大提高了处理速度,降低了计算成本
为什么对AI代理特别重要?
AI代理工作方式如下:
- 接收用户输入
- 选择一个动作(如搜索网页、运行代码等)
- 执行该动作并获得结果
- 将结果添加到上下文中
- 基于更新后的上下文选择下一个动作
- 重复直到任务完成
在这个过程中:
- 上下文不断变长(每次添加新的动作和结果)
- 输出通常很短(如函数调用)
- 因此,输入对输出的比例很高(Manus中约为100:1)
KV缓存的经济效益:
- 使用Claude模型时,缓存的输入令牌成本为0.30美元/百万令牌
- 未缓存的输入令牌成本为3美元/百万令牌
- 这是10倍的差异!
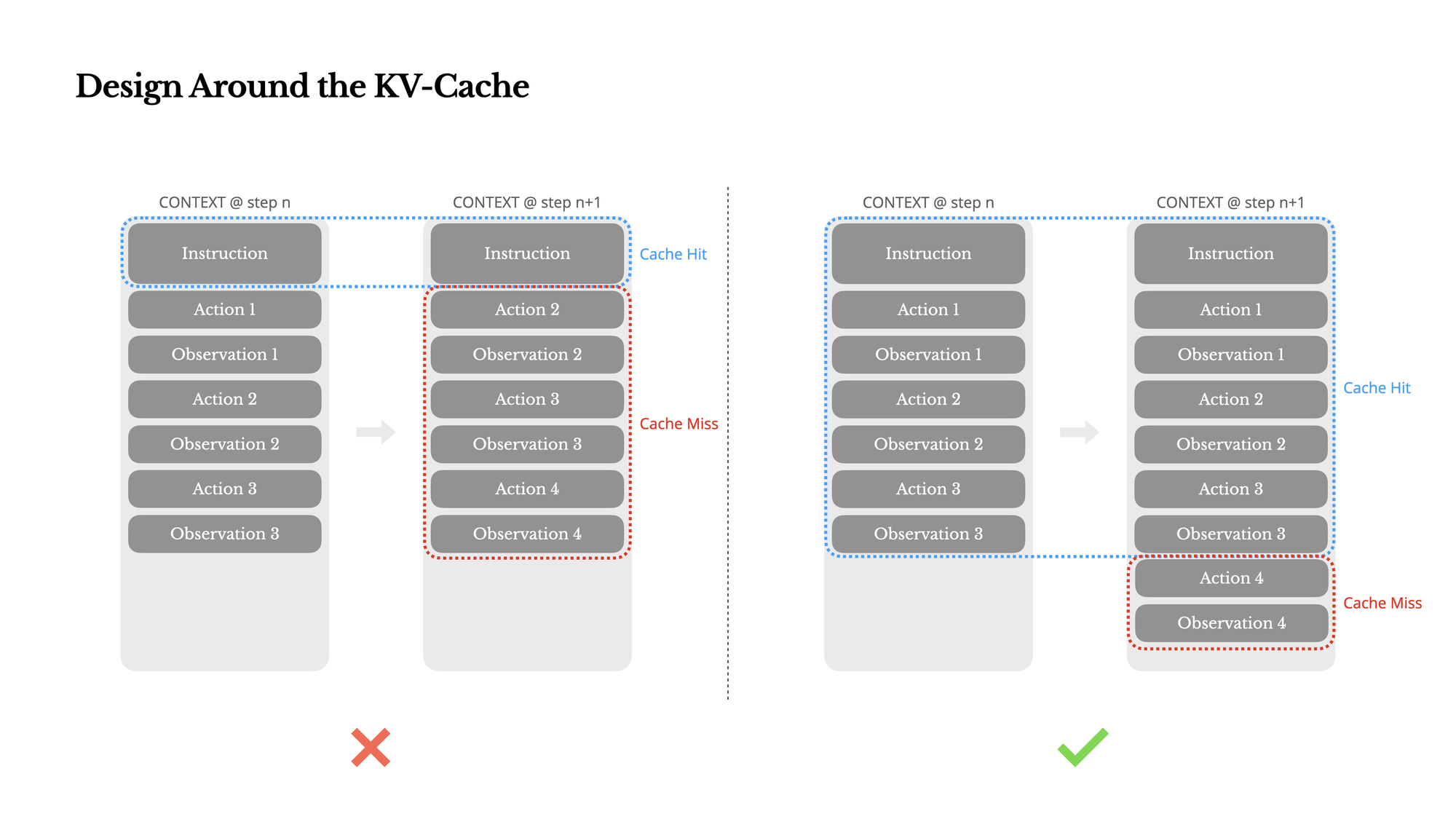
如何提高KV缓存命中率?实用技巧:
- 避免在系统提示开头包含时间戳
- 即使一个字符的变化也会导致后续缓存失效
- 确保序列化方式一致(例如JSON键的顺序)
- 模型按字符串处理文本:AI模型不理解"JSON语义",它只看到一系列字符
- 缓存比较是基于精确匹配:即使只有顺序不同,也会被视为完全不同的输入
- 自回归处理机制:模型从左到右处理文本,任何差异都会导致从该点开始的缓存失效
- 使用有序字典或对象
- 实现一致的序列化函数
- 考虑对键进行排序(如字母顺序)
- 明确标记缓存断点
- 在系统提示结束处设置缓存断点
只追加内容,不修改已有内容为什么JSON键顺序如此重要?在AI代理系统中,JSON对象中键的顺序看似微不足道,但实际上可能对性能和成本产生巨大影响。这是因为:看看这个例子:
❌ 错误示例:
{
"time": "14:30:22",
"action": "search"
}
✅ 正确示例(保持一致的键顺序):
{
"action": "search",
"time": "14:30:22"
}
虽然这两个JSON对象从人类角度看是完全相同的(包含相同的信息),但从模型处理的角度看,这是两个完全不同的文本序列。如果系统不保持一致的键顺序,每次生成类似结构时可能会产生不同顺序,导致缓存命中率大幅下降。实用解决方案:
# Python示例:确保一致的JSON序列化
def serialize_action(action, time):
# 总是按相同顺序构建字典
return json.dumps({
"action": action, # 始终将action放在前面
"time": time
})
# 或使用排序键
def consistent_json(obj):
return json.dumps(obj, sort_keys=True)
保持提示前缀稳定
❌ 错误示例:
当前时间:2025-07-21 14:30:22
你是一个AI助手...
✅ 正确示例:
你是一个AI助手...
对于开发者来说,这意味着您应该设计一个稳定的系统提示结构,并确保只向上下文追加内容,而不是修改或重写它。
工具空间管理:遮蔽比删除更好
问题背景:
随着AI代理能力增强,可用工具数量会迅速增长。在Manus这样的系统中,用户甚至可以自行添加工具。但工具过多会导致:
- 模型可能选择错误的工具
- 执行效率降低
- 推理路径变得复杂
为什么不能动态添加/删除工具?
直觉上,我们可能想要根据需要动态加载工具,类似于RAG(检索增强生成)。但这有两个问题:
- 缓存失效:工具定义通常位于上下文前部,修改会导致整个缓存失效
- 模型混淆:如果先前的动作引用了现在已不存在的工具,模型会感到困惑
Manus的解决方案:使用状态机和遮蔽
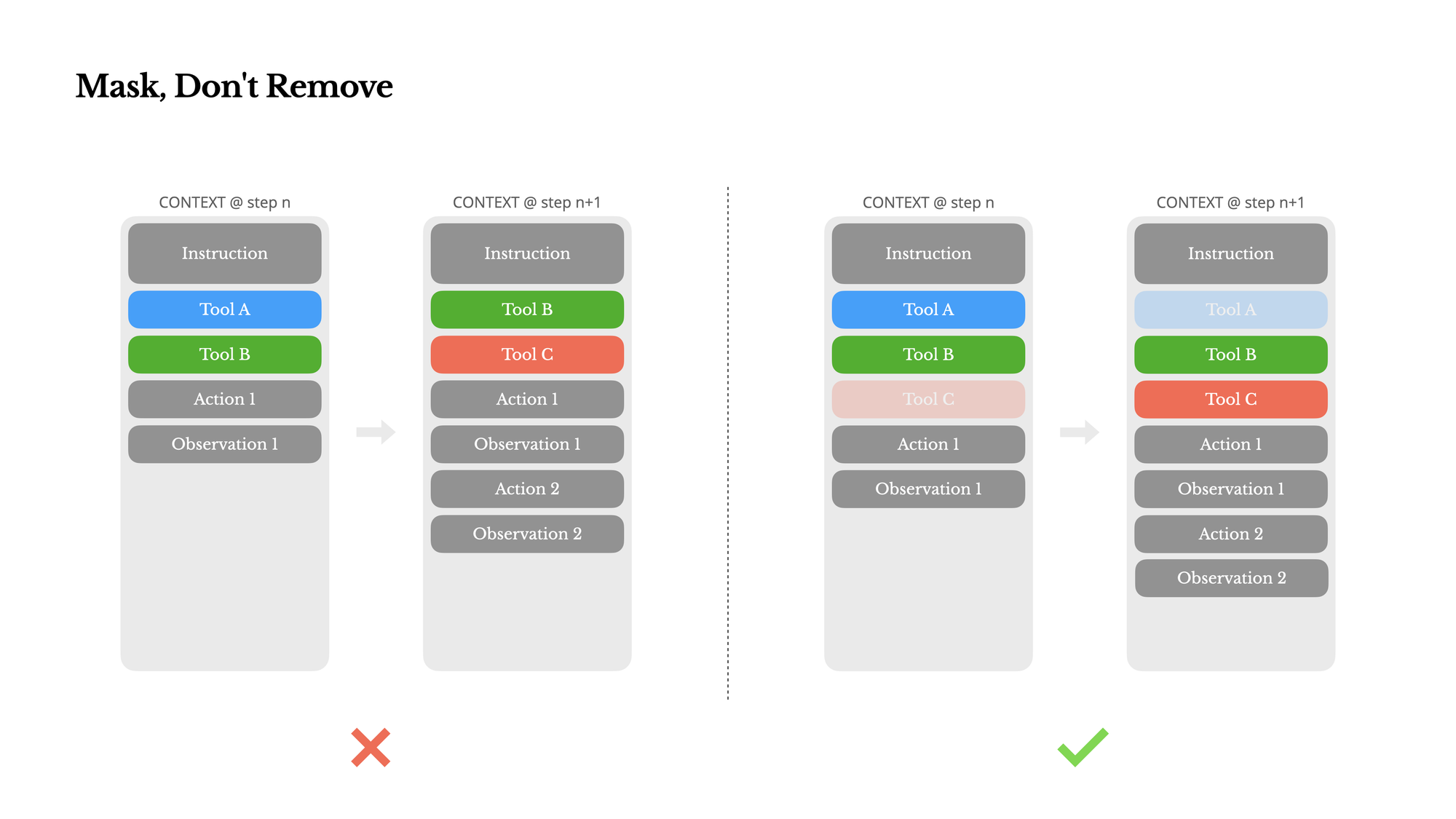
不是物理删除工具,而是:
- 使用上下文感知的状态机管理工具可用性
- 在解码阶段遮蔽(mask)某些选项,防止模型选择特定工具
函数调用的三种模式(以Hermes格式为例):
指定模式:模型必须从特定子集调用函数
<|im_start|>assistant<tool_call>{"name": "browser_
必需模式:模型必须调用函数,但可以自由选择哪一个
<|im_start|>assistant<tool_call>
自动模式:模型可以选择调用或不调用函数
<|im_start|>assistant
实用技巧:工具命名策略
Manus有意设计具有一致前缀的工具名称:
- 所有浏览器相关工具以
browser_开头 - 所有命令行工具以
shell_开头
这样可以轻松限制模型在特定时刻只能选择某一类工具,而无需修改上下文。
文件系统作为扩展上下文:解决记忆限制
问题背景:
即使现代大型语言模型有12.8万令牌的上下文窗口,在实际代理场景中仍面临三个问题:
- 观察结果过大:网页或PDF等内容可能非常庞大,轻松超过上下文限制
- 性能下降:模型性能在超过一定上下文长度后会下降
- 成本高昂:长输入意味着更高的API调用成本
传统解决方案的缺陷:
许多系统使用上下文截断或压缩策略,但这可能导致关键信息丢失。你永远不知道哪个细节在十步后会变得重要。
Manus的创新方法:文件系统作为上下文扩展
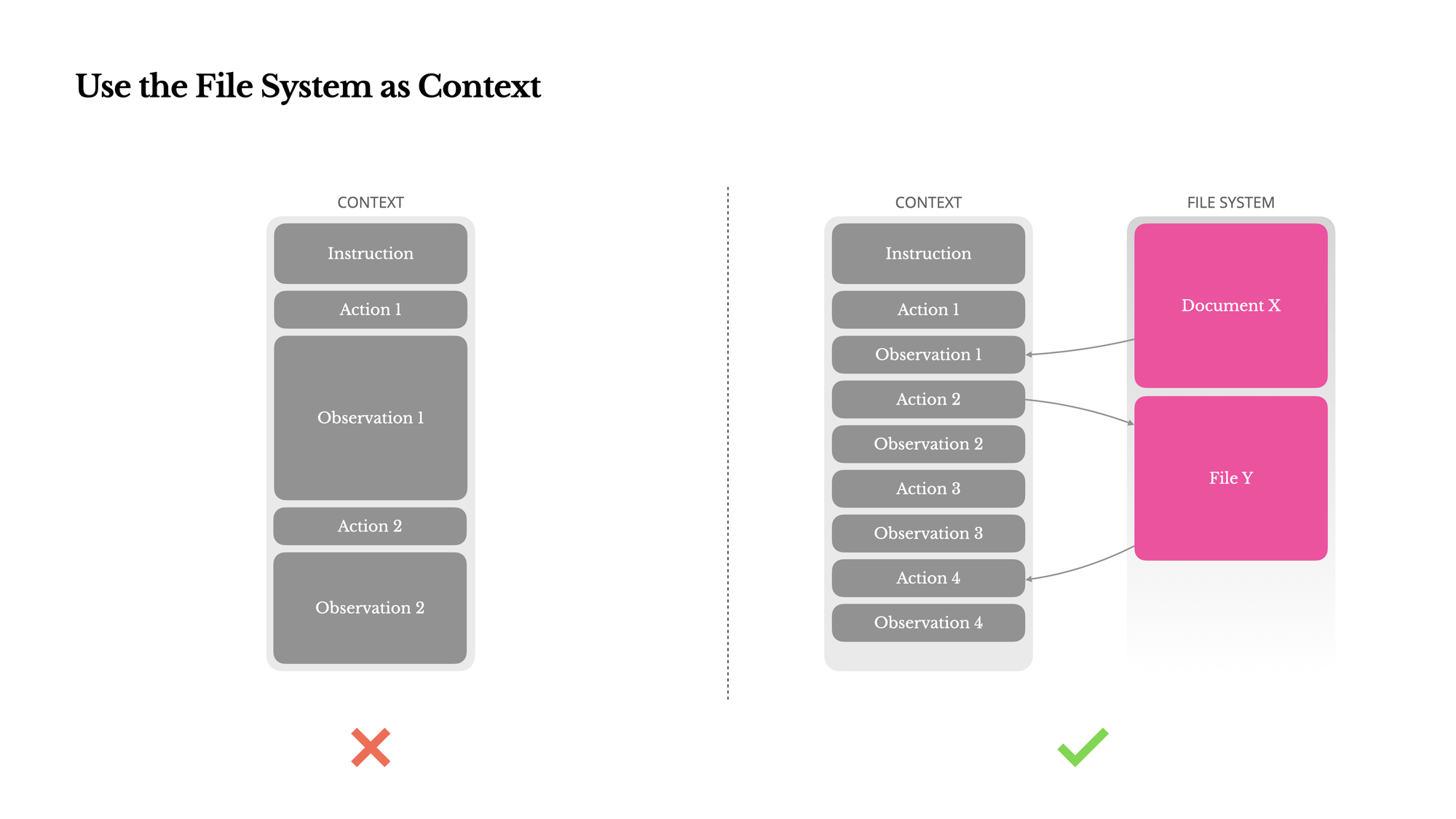
将文件系统视为无限大小的外部记忆:
- 代理可以将信息写入文件
- 需要时再从文件中读取
- 信息永久保存,不受上下文窗口限制
实际应用示例:
# 当处理大型网页时
1. 代理下载网页内容
2. 将完整内容保存到文件:webpage_content.txt
3. 在上下文中只保留URL和文件路径
4. 需要信息时,读取文件内容
可恢复的压缩策略:
Manus的原则是:只要信息可以恢复,就可以从上下文中移除。例如:
- 网页内容可以删除,只要保留URL(可以重新访问)
- 文档内容可以省略,只要保留文件路径(可以重新读取)
这种方法启发了作者对未来AI模型的思考:如果状态空间模型(SSM,一种比Transformer更高效的模型架构)能掌握文件系统交互,它们可能成为更高效的代理基础。
通过复述维持注意力:解决长任务中的目标遗忘
有趣的观察:
如果您使用过Manus,可能会注意到它有个特别的习惯:当处理复杂任务时,它会创建一个todo.md文件,并随着任务进行不断更新,勾选已完成的项目。
这不只是一个可爱的习惯,而是一个精心设计的机制。
问题背景:
Manus中的典型任务平均需要约50个工具调用。在这么长的过程中,模型容易:
- 偏离主题
- 忘记最初的目标
- 在复杂任务中迷失方向
解决方案:复述重点内容
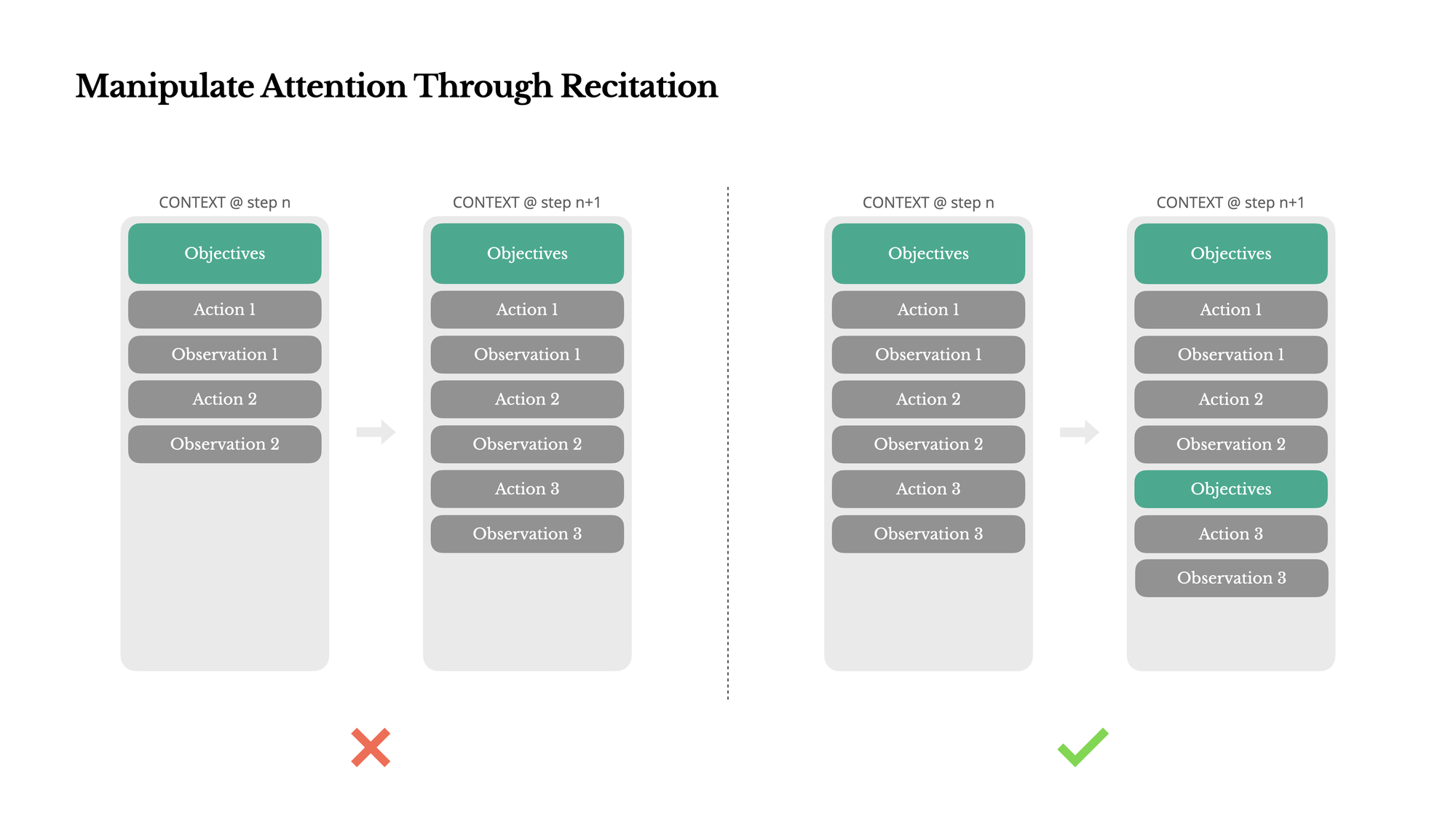
通过不断重写待办事项列表,Manus实际上是在:
- 将任务目标重复写入上下文末尾(最近的部分)
- 将全局计划推入模型的注意力范围
- 避免"迷失在中间"问题(模型对上下文中间部分的注意力较弱)
实用启示:
当设计需要多步骤完成的AI任务时,让AI定期"复述"当前目标和进度是保持任务聚焦的有效方法。这可以是:
- 待办事项列表
- 进度摘要
- 目标回顾
保留错误信息:AI代理的"错题集"机制
现实认知:代理会犯错
AI代理会出错,这不是bug而是正常现象:
- 语言模型会产生幻觉
- 环境可能返回错误
- 外部工具可能失败
- 意外情况随时可能发生
常见但错误的做法
当错误发生时,开发者通常倾向于:
- 清理错误记录
- 重试失败的动作
- 重置模型状态
这看起来更干净、更可控,但实际上弊大于利。
"错题集"概念:从失败中学习
Manus采用的方法类似于为AI建立一个"错题集"。就像学生通过错题集避免重复犯相同的错误,AI代理通过保留错误信息来改进自己的行为。

错题集机制的工作原理:
- 记录失败经验:
- 就像学生在错题集中记录做错的题目和正确答案
- AI代理在上下文中保留失败的动作和错误信息
- 隐式学习:
- 学生复习错题集时会思考"我之前为什么做错了"
- AI通过上下文中的错误记录隐式调整其行为概率分布
- 避免重复错误:
- 学生在下次遇到类似问题时会想起错题集中的教训
- AI在决策时会自然降低选择相似失败路径的概率
与传统错题集的不同:
- 无需显式标记:不需要明确告诉AI"这是错误示范"
- 即时学习:不需要特意"复习"错题集
- 概率性调整:不是硬性规则,而是概率调整
实例说明:为什么保留错误记录更有效
# 错误的方式
Agent: 我将运行命令 `rm file.txt`
[错误发生,但被清除]
Agent: 让我尝试其他方法...
# 更好的方式(错题集方法)
Agent: 我将运行命令 `rm file.txt`
System: 错误:文件不存在
Agent: 我明白了,文件不存在。让我先检查当前目录中有哪些文件...
编程任务中的错题集效应
AI: 我将编写一个解析JSON的函数。
[AI编写代码]
```javascript
function parseJSON(jsonString) {
return JSON.parse(jsonString);
}
const data = parseJSON(userInput);
console.log(data.name);
用户测试: 当输入无效JSON时发生错误
AI: 我注意到如果输入无效JSON,会抛出异常。我应该添加错误处理。 [AI修改代码]
function parseJSON(jsonString) {
try {
return JSON.parse(jsonString);
} catch (error) {
console.error("Invalid JSON input:", error.message);
return null;
}
}
const data = parseJSON(userInput);
if (data) {
console.log(data.name);
}
用户: 现在请编写一个解析XML的函数
AI: 根据之前的经验,我将确保包含错误处理。 [AI编写新代码]
function parseXML(xmlString) {
try {
const parser = new DOMParser();
const xmlDoc = parser.parseFromString(xmlString, "text/xml");
// 检查解析错误
const parseError = xmlDoc.getElementsByTagName("parsererror");
if (parseError.length > 0) {
throw new Error("Invalid XML input");
}
return xmlDoc;
} catch (error) {
console.error("XML parsing failed:", error.message);
return null;
}
}
const xml = parseXML(userInput);
if (xml) {
// 处理XML
}
在这个例子中,AI从第一个任务中"学到"了需要添加错误处理,并将这一教训应用到了第二个任务中,即使没有明确要求添加错误处理。
实际应用建议
如果您想在自己的AI代理系统中实现这种"错题集"机制,可以:
- 设计富有信息的错误消息:
- 不要只返回"错误",而是提供具体原因
- 例如:"文件不存在"比"操作失败"更有帮助
- 保持上下文连贯性:
- 不要在错误发生后重置或清除上下文
- 让错误成为上下文历史的自然部分
- 考虑长期任务的错误管理:
- 对于复杂任务,可以考虑定期"总结"遇到的错误
- 例如:"到目前为止,我尝试了X、Y和Z方法,其中X和Y失败了,原因是..."
作者认为,错误恢复能力是真正智能代理行为的重要标志,但在大多数研究和评估中被忽视了。
避免少样本陷阱:多样性的重要性
什么是少样本提示(Few-shot prompting)?
少样本提示是一种常用技术:提供几个示例,让AI模型学习并模仿这种模式。例如:
问题:2+2=? 答案:4
问题:3+5=? 答案:8
问题:7+9=? 答案:
在代理系统中的问题:
语言模型是优秀的模仿者,但这在代理系统中可能适得其反。如果上下文中充满类似的动作-观察对,模型会倾向于重复这种模式,即使不再适用。
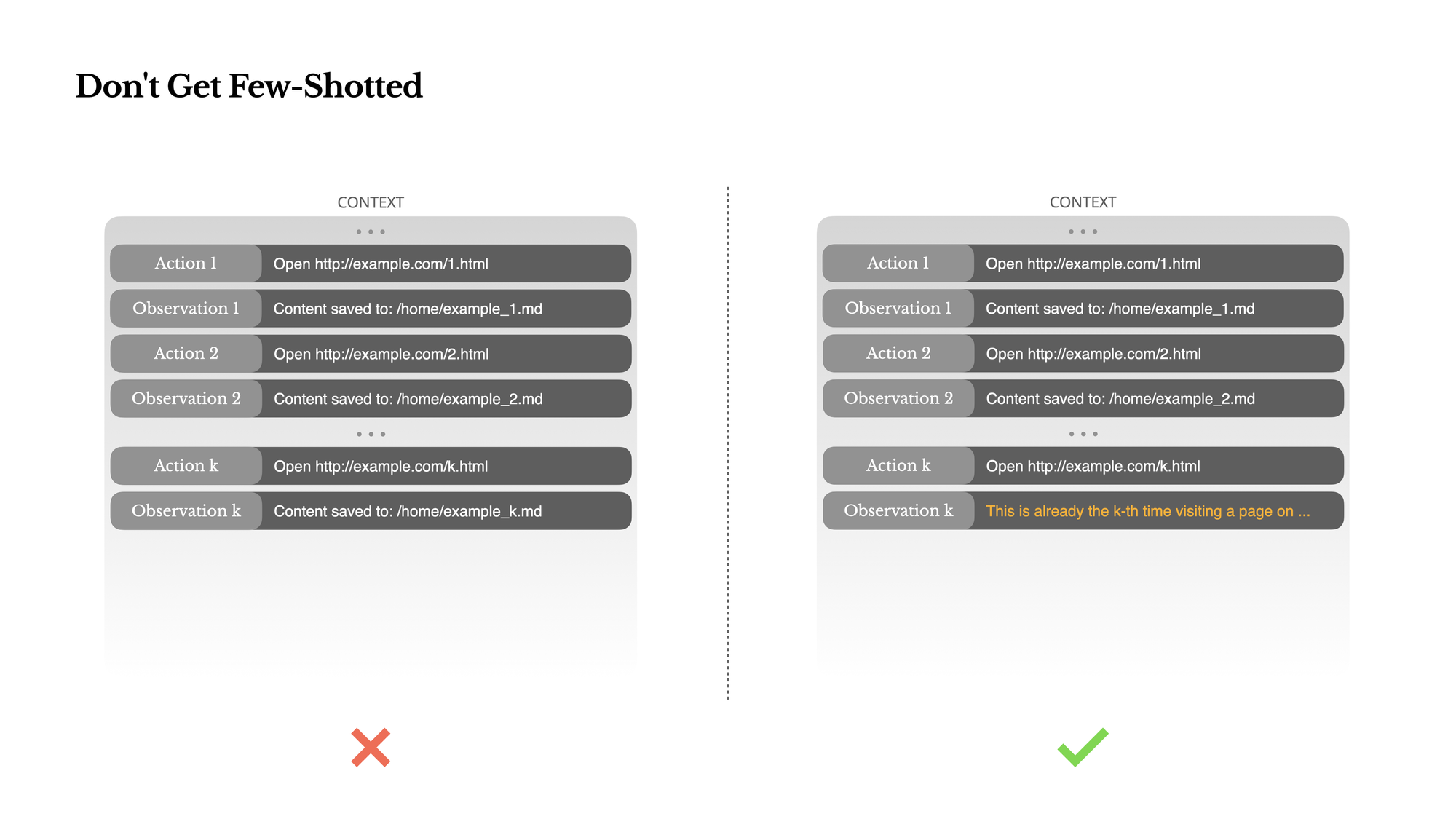
实际例子:简历审查任务
当使用Manus审查20份简历时,代理容易陷入机械重复:
- 对第一份简历执行了一系列动作
- 这些动作-观察对进入上下文
- 处理后续简历时,倾向于执行完全相同的动作序列
- 导致过度泛化、忽略每份简历的独特性
Manus的解决方案:引入结构化多样性
在上下文中有意引入小的变化:
- 不同的序列化模板
- 替代性措辞
- 顺序或格式的微小变化
这种"受控随机性"打破了模式,防止代理陷入重复。
实用启示:
如果您设计一个需要处理多个类似项目的AI代理(如审查多份文档、分析多个数据集),确保:
- 不要让上下文变得过于模式化
- 鼓励代理为每个项目"重新思考"
- 引入适当的多样性
实用总结:开发自己的AI代理系统
基于Manus团队的经验,以下是构建有效AI代理系统的关键原则:

- 优化KV缓存
- 保持系统提示稳定
- 只追加内容,不修改已有内容
- 注意序列化的一致性
- 智能管理工具空间
- 使用遮蔽而非删除工具
- 采用一致的工具命名约定
- 使用状态机控制工具可用性
- 扩展记忆能力
- 将文件系统作为外部记忆
- 设计可恢复的压缩策略
- 只保留必要信息在主上下文中
- 维持长期目标关注
- 让代理定期"复述"任务目标
- 使用待办事项列表或进度摘要
- 将重要信息放在上下文末尾
- 实现"错题集"机制
- 保留失败尝试及其结果
- 提供丰富的错误信息
- 让AI自主从错误中学习
- 培养错误恢复能力
- 避免过度模式化
- 引入适当的多样性
- 防止代理陷入重复模式
- 鼓励针对每个任务"重新思考"
扩展阅读资源
如果您想深入了解文章中提到的概念,以下是一些入门资源:
- 上下文学习:
- In-Context Learning - 了解基础概念
- Prompt Engineering Guide - 实用提示工程技巧
- KV缓存:
- KV Caching Explained - 入门解释
- vLLM文档:前缀缓存 - 技术实现
- 代理系统:
- 少样本学习:
- Few-shot Prompting Guide - 实用指南
- 状态空间模型:
- Neural Turing Machines - 了解早期外部记忆概念